

大家好,我是SEO小平,SEO捕鱼大师,9年独立站卖家,一直从事各个国家本土语言的独立站SEO实操。
最近我搞了一场培训主要是教大家做好英语网站的SEO的同时开拓小语种,用AI做各个国家的本土语言独立站。
我发现很多朋友不会查询网站的收录,也叫网站的索引,英语就是index。
所以今天SEO小平详解一下谷歌SEO怎么查自己网站的收录数量。
第一:怎么查询Google收录数量?
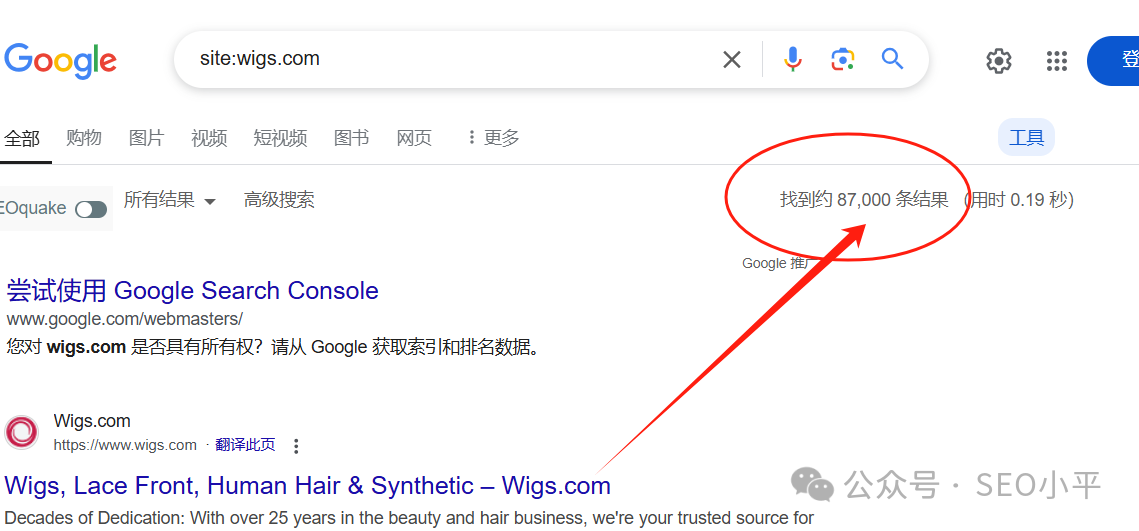
方法一:要检查网站是否被Google收录,最简单的方法是使用site:操作符,在Google搜索框中输入site:yourwebsite.com(注意这里要替换,用你的域名替换“yourwebsite.com”),按回车。如果有结果显示,说明网站已被收录;如果没有,可能尚未被收录。
以前是直接SERP会告诉你有多少结果数,现在你需要多操作一步,在搜索框下边要点击这个【工具】按钮,英语界面的话就是【Tool】,就能告诉你收录数量了。不需要你到谷歌页脚去一直翻页到最后一页来计算收录数,你要是遇到amazon.com 这种大型网站收录几十亿,你怎么靠翻页去查询。
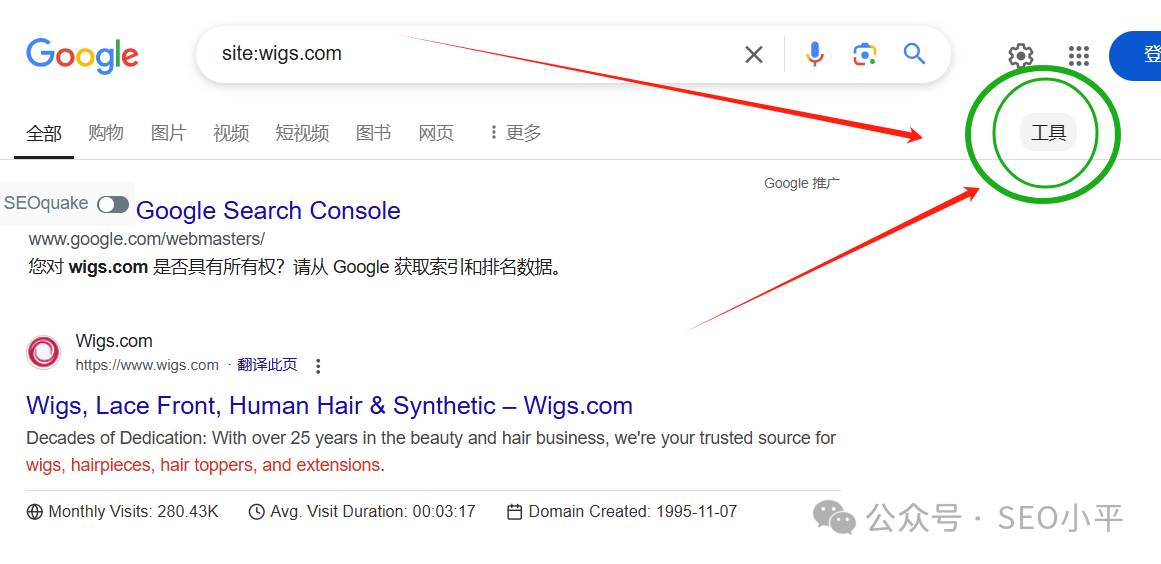
如下截图,8700就是这个网站查出来的收录数量。
方法二:使用Google搜索控制台(GSC),登录后查看“覆盖范围”报告,了解详细的收录情况,包括可能的技术问题。更多信息请见Google Search Console Help。如下截图是GSC的收录报告。
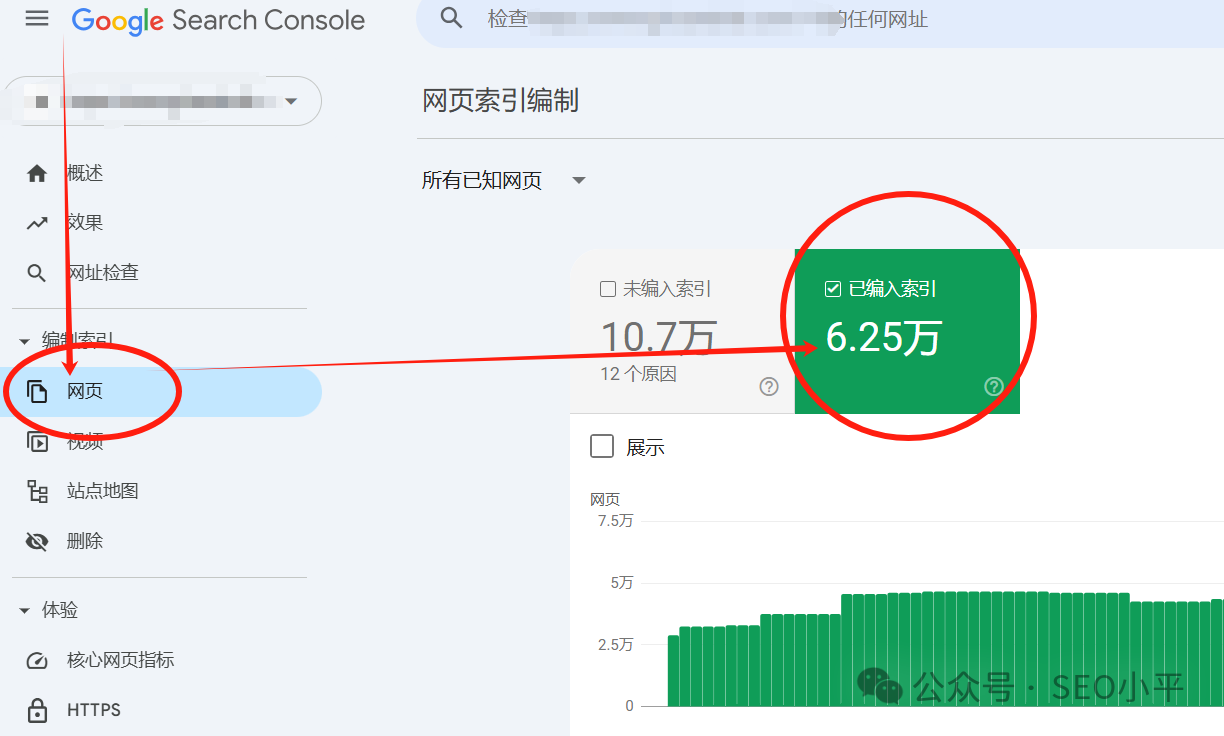
注意:方法一是能查询你的竞争对手,也能查询你自己,方法二是只能查询你自己,因为必须要有谷歌GSC后台,除非别人授权给你了他的GSC后台。
为了更清晰地展示两者的差异,我们可以用表格来总结:
| 方面 | site:操作符 | Google搜索控制台(GSC) |
|---|---|---|
| 目的 | 主要为用户搜索特定网站内容 | 为网站所有者提供全面的索引监控和优化工具 |
| 返回所有被索引的URL | 否,可能遗漏部分被索引的页面 | 是,显示所有被索引的URL,包括技术问题页面 |
| 结果排序 | 无明确排名,通常最短URL在顶部,其他随机 | 按报告分类,方便分析 |
| 使用场景 | 快速检查网站部分收录情况 | 详细审计索引状态,排查问题 |
| 局限性 | 不适合全面审计,可能受算法和时间延迟影响 | 数据更新可能有延迟,但更可靠 |
这个表格来源于Google Search Central和Google Search Console Help,帮助你更直观地理解两者的区别。
第二: 为什么GSC和site:操作符结果不一致
有经验的SEO会发现:GSC显示的收录数量可能与site:命令搜索结果不同,当然我们说的是同一个网站哈。这个问题也同行困扰SEO小平很多年。我用DeepSeek深度思考搜了一下答案,觉得这些说法是有道理的,所以列出来:
1. 数据来源与更新频率差异
• GSC数据:基于Google索引数据库,反映已确认收录的页面(需通过Google爬虫验证),但数据更新可能有 1-3天延迟。
• **site: 命令**:实时展示当前搜索索引中的页面,但结果受缓存、个性化搜索(如用户地理位置、历史记录)及算法过滤(如去重、质量评估)影响。
2. 索引状态与排除机制
• GSC的“已编入索引”页面:
◦ 包含Google认为 有价值且无技术问题 的页面。
◦ 排除被标记为“已抓取但未编入索引”的页面(如重复内容、低质量页面)。
• **site: 结果**:
◦ 可能包含 已被抓取但尚未正式编入索引 的页面。
◦ 部分页面可能因临时性策略(如沙盒期新站)被隐藏。
3. 分页限制与结果截断
• **site: 命令最多显示约1000条结果**,超出部分会被截断(即使实际索引量更大)。
• GSC显示的收录量是精确值(但需注意查看是否有分页筛选,如按设备类型、国家区分)。
4. URL规范化与重复内容
• 规范版本(Canonical)优先:
◦ GSC可能仅统计规范化的主URL。
◦ site: 命令可能显示多个重复URL(如带参数版本、HTTP/HTTPS混用)。
• Google可能合并相似页面,导致实际索引量小于抓取量。
5. 技术限制与屏蔽规则
• robots.txt 或 noindex:
◦ 若页面被 robots.txt 屏蔽或标记 noindex,GSC会标记为“已阻止”,但 site: 可能仍显示旧缓存。
• 动态页面/JavaScript渲染问题:
◦ GSC可能无法正确渲染JS内容导致漏报,而 site: 结果可能包含已渲染页面。
6. 属性验证范围差异
• GSC需验证网站所有权,数据仅涵盖已验证的协议(HTTP/HTTPS)、域名(带www或不带)或子目录。
• site: 命令可能混合不同子域名、协议版本的结果(如 site:example.com 包含 blog.example.com)。
第三:中国人常见的重要的错误,site后面加中文冒号
SEO小平接触到很多人查收录会情不自禁的使用中文的冒号,许多中国SEO从业者可能使用中文冒号(:)代替英文冒号(:)输入site:操作符。虽然Google会返回结果,但这些结果往往不是网站被收录的页面,而是包含“site”和“:example.com”等关键词的普通网页。这可能导致误判网站收录情况。
以shein.com 为例,使用中文冒号的结果是一亿一千一百万,如下截图:

使用英语冒号的结果是一千六百万,如下截图:
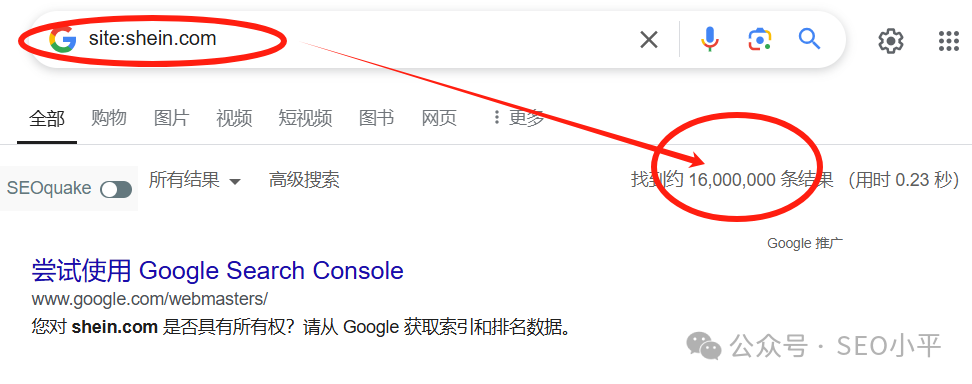
原因:中文冒号和英语冒号表达的意义不同
- 中文冒号(:)在Unicode编码中是U+FF1A,而英文冒号(:)是U+003A。Google的搜索引擎是基于英文字符集设计的,因此它只识别英文冒号(:)作为搜索操作符的一部分。
- 当你输入site:example.com时,Google并不会将其解释为site:操作符,而是将“site”和“:example.com”视为独立的搜索关键词。这意味着搜索结果可能包含“site”和“example.com”这两个词的页面,但这些页面并不一定是你的网站被收录的证据。
后果是什么?
- 你可能会误以为这些搜索结果是你的网站被Google收录的页面,但实际上,它们只是包含相关关键词的普通网页。
- 如果你用site来查竞争对手的收录情况,这会导致你对网站收录情况的判断出现偏差,可能高估或低估了竞争对手,自己把自己吓尿了,结果发现是自己搞错了。
如何避免?
输错就让旁边同事抽你两耳光,这是最有效的方法
- 比较慢的方法就是,始终使用英文冒号(:)来书写site:操作符。例如,正确的写法应该是site:example.com,而不是中文冒号 site:example.com。
好了,关于网站收录的查询我们今天就讲到这里,祝大家早日拿到询盘,拿到订单。
来源公众号: SEO小平(ID:googleseoxp)死磕谷歌SEO的隔壁老王。
本文由 @SEO小平 原创发布于奇赞平台,未经许可,禁止转载、采集。
该文观点仅代表作者本人,奇赞平台仅提供信息存储空间服务。








