

目录
一.谷歌抓取的工作原理
二.为什么要重视谷歌抓取?
三.网站被抓取大概需要多长时间
四.如何检测抓取的情况
五.常见的网站抓取问题有哪些?要如何避免?
01 谷歌抓取的工作原理
想要更好地理解谷歌抓取,我们可以先来了解另一个概念——网络爬虫,谷歌官方一般把它叫做Google Spider、Google Bot。只听网络爬虫这个名字,可能会觉得比较抽象,下面我们来举个例子,可能会让它变得形象起来了:你可以把整个世界的网络想象为一个巨大蜘蛛网,而搜索引擎本身有属于它的一只爬虫程序,这个程序会像蜘蛛一样在这巨大的网络上爬行,并在爬行的同时收集信息。
在做 SEO 工作的时候,维持搜索引擎爬虫与网站之间的关系是非常重要的,我们必须要尽量让它能够完整爬取你网站上的优质内容,否则会对你的网站 SEO 有影响(后面都会说到的)。
那抓取指的就是,搜索引擎的爬虫来你的网站上爬取、下载网站资料的这个动作,在谷歌官方的文件上一般被译为“抓取”,但业内也会把这个过程叫做爬取。在这个阶段谷歌的爬虫会在你的网站上爬取所有能爬到的资料,包含你的网页内容、程序代码、图片等所有的网页信息。
02 为什么要重视谷歌抓取?
这就不得不提到搜索引擎的工作原理了,我们可以简单把搜索引擎运作原理分成四个阶段:抓取→收录→分析搜索意图→曝光在搜索结果
抓取,就在最开始的第一阶段。也就是说,如果爬虫连你的网站都没有爬取到,那根本就没有之后被收录、呈现在SERP上的机会。抓取就是这一切的前提,如果谷歌连爬取都不能很好地完成,那优化得再好也没用。因为谷歌爬虫根本看不到你网站里面的资料。
03 网站被抓取大概需要多长时间
一般来说,对于新网站来说,需要的时间可能较长几周或者几个月都有可能,而如果是被谷歌认可的高质量网站,速度可能要快一些,几个小时候或者几天就能被抓取。这也只是一般情况,也不排除有的新网站,一上线就被爬虫注意到,很快就完成抓取的情况出现。
之所以没有一个固定的范围,是因为谷歌抓取收到多种因素的影响:
1.网站规模
对于小型网站(例如只有几个页面的个人博客),谷歌可能在几天到几周内就能完成首次抓取并收录大部分页面。如果网站结构简单,内部链接良好,内容更新不频繁,爬虫可能会相对快速地遍历所有页面。
例如,一个有10-20个页面的简单企业宣传网站,可能在首次提交网站地图后的1-2周内就会被较好地抓取。
2.网站内容更新频率
经常更新内容的网站(如新闻网站)会吸引爬虫更频繁地访问。如果是一个每天更新多篇新闻文章的网站,谷歌可能会每天或每隔几天就来抓取新内容。
以知名新闻媒体网站为例,它们的新文章可能在发布后的几小时内就会被谷歌抓取,因为谷歌知道这些网站是内容的优质来源,并且更新机制比较固定。
3.网站结构和代码质量
具有清晰、合理的网站结构(如良好的层次结构和内部链接)和简洁、规范代码的网站更容易被抓取。如果网站使用了复杂的JavaScript框架或者有大量的嵌套表格等不利于搜索引擎理解的代码结构,会阻碍爬虫的抓取。
例如,内部链接逻辑清晰的电商网站,会比一个代码混乱、结构复杂的同类型网站更快地被抓取,甚至可能会快几个星期或数月。
4.网站权重和历史数据
已经建立了较高权重和良好声誉的老网站通常会被谷歌更频繁和快速地抓取。
例如,像维基百科这样的高权重网站,其新页面或更新后的页面往往能在短时间内被抓取,可能在数小时内,因为谷歌对这类权威网站有较高的信任度。
相反,新建立的网站,没有任何外链指向它,也没有历史数据证明其内容质量,可能需要更长时间才能被谷歌注意到,可能要数月。
5.竞争程度
在竞争激烈的领域(如金融、科技、电商),有大量的网站争夺谷歌的抓取资源。如果你的网站处于这样一个竞争激烈的行业,可能需要优化网站以突出自身优势,吸引谷歌爬虫。
例如,在电商领域,头部电商品牌的网站可能会被优先抓取,而新的小电商网站可能需要花费更多时间来让谷歌关注到,可能要3-6个月甚至更久,直到网站通过优化和外部链接建设等方式提升自己的排名。
6.谷歌算法更新和服务器资源
谷歌会定期更新算法,这些更新可能会影响抓取优先级。同时,谷歌自身服务器资源的分配也会影响抓取时间。
例如,当谷歌重点关注某一新兴领域(如新的热门技术相关网站)的内容更新时,可能会暂时减少对其他不太受关注领域网站的抓取频率。
04 如何检测抓取的情况
其实一般来说只要你的网站是正常的,没有悄悄搞小动作,被爬取就不是难题。那么,我们要如何检查谷歌是否准确完整地爬取你的网站呢?常见的方法之一就是通过Search Console的报表(如下图)。
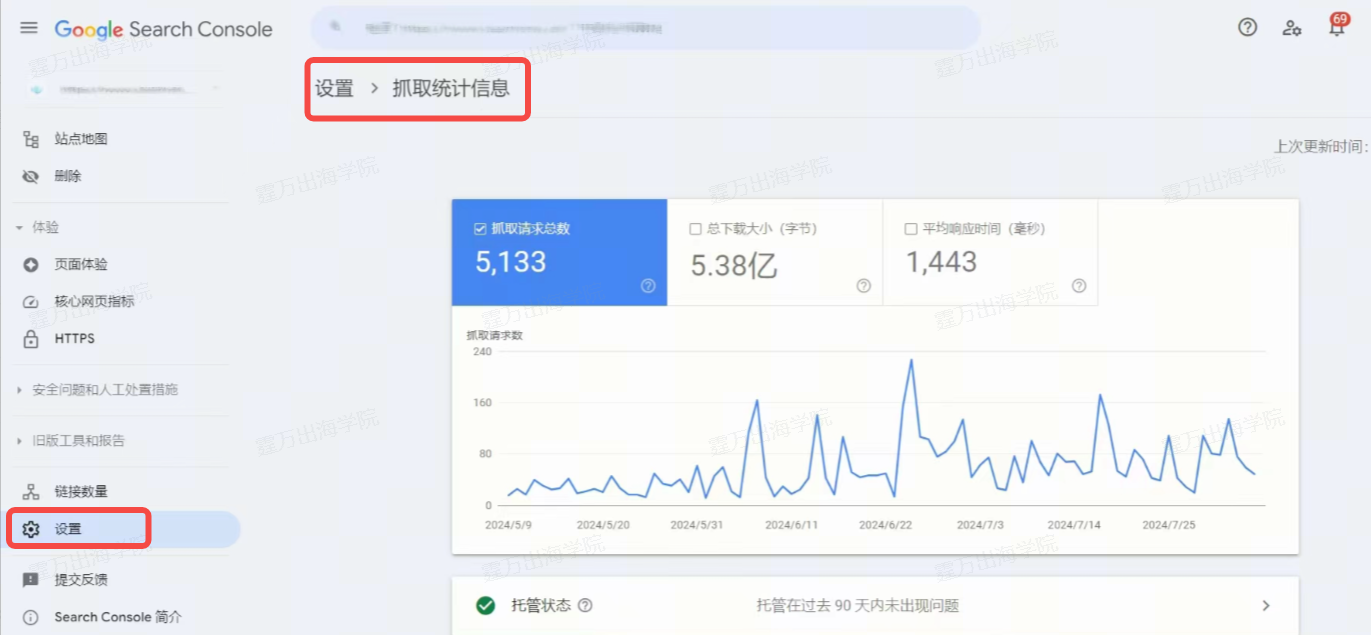
从Search Console的“设置>抓取统计信息”中,可以看到每日抓取的网页数目,这个图表可以清晰展现出谷歌每天来爬你网站的时候,都爬了多少个网页,一般图表会在一个区间范围内波动。大多数情况下,谷歌每天来爬多少网页取决于三件事情:
- 你的网站在市场上有多重要、网站的SEO权重有多高(也就是所谓的 Crawl Budget)
- 你的网站架构是否有使用不利于爬虫的技术,导致爬虫不容易爬到资料
- 你是否有主动阻挡谷歌爬你的网站,比如meta robots、robots.txt
还有一个要注意的是,如果谷歌爬取你网页的数量与你网站页面总数相差太大的话,对 SEO 也是不太好的,比方说你的网站共有8,000个网页,但谷歌每天只来爬取50 页~100 页左右,这就不太行了,500~1,000 之间才比较正常。
05 常见的网站抓取问题有哪些?要如何避免?
1.抓取频率问题
抓取频率过高可能会对网站服务器造成较大的负载压力,导致网站响应变慢甚至崩溃。而抓取频率过低则会使网站内容更新不及时被搜索引擎索引,影响网站的搜索排名和流量。
比如,对于一个小型电商网站,服务器配置较低,如果谷歌等搜索引擎频繁抓取,可能会出现用户访问商品页面时加载缓慢的情况。相反,如果是一个新闻网站,抓取频率过低,可能会导致新闻文章不能及时被收录,在搜索引擎结果页面(SERP)中出现的时间延迟,用户搜索相关新闻时就找不到该网站的最新内容。
解决方案:
可以通过搜索引擎提供的工具(如Google Search Console)来设置抓取频率的上限。同时,优化网站服务器性能,如升级服务器配置、采用内容分发网络(CDN)等方式来承受更高的抓取频率。
2.抓取深度问题
搜索引擎蜘蛛可能不会抓取网站的深层页面。这通常是因为网站结构复杂、内部链接不清晰或者爬虫在抓取过程中遇到了阻碍,如死链接、无限循环链接等。
正常来说,一个企业网站会有多层级的产品目录,从产品大类到小类再到具体产品页面。如果内部链接设置不合理,比如某些小类产品页面没有正确链接到具体产品页面,爬虫可能就无法深入抓取到具体的产品介绍页面,这些页面就无法被成功爬取收录,从而影响产品在搜索引擎中的曝光度。
解决方案:
优化网站结构,简化网站的层级。合理设置内链,确保每个页面都可以通过最多3-4个链接从首页到达。定期检查网站的链接健康状况,修复死链接和循环链接。可以使用专业的网站链接检查工具。
3.被阻止抓取
网站可能因为误操作或者安全设置等原因,阻止了爬虫的抓取。这可能是通过 robots.txt文件设置错误、服务器防火墙阻止或者采用了某些会阻止爬虫的安全插件导致的。
解决方案:
检查robots.txt文件,确保文件中的规则允许搜索引擎爬虫抓取需要收录的页面。对于服务器防火墙和安全插件,需要调整其设置,将合法的搜索引擎爬虫IP范围(可以从搜索引擎官方获取)设置为允许访问。同时,可以通过搜索引擎的工具(如Google Search Console)查看是否有抓取被阻止的提示信息并进行针对性处理。
4.重复内容抓取的问题
网站内部存在大量重复内容,如多个页面内容相似或者由于技术原因(如URL参数不同但内容相同)产生的重复页面。这会让爬虫浪费资源抓取重复信息,并且可能导致搜索引擎对网站质量产生误解,影响排名。
例如,一个电商网站在产品列表页面和产品详情页面可能会因为筛选参数等原因出现内容重复的情况。产品列表页面显示了产品的图片、名称和价格,而产品详情页面在加载不完全时也显示相同的内容,搜索引擎蜘蛛可能会将这两个页面视为重复内容。
解决方案:
对网站内部的重复内容进行清理或优化。可以采用301重定向将重复页面重定向到主要页面。对于因为参数产生的重复内容,可以通过规范URL结构,使用canonical标签来告诉搜索引擎哪个页面是主要页面,应该重点抓取和收录。
5.最基础的网页问题以及SEO问题
如果你有很多404的网页,或是网站上有很多不必要的内容,可能都会影响爬虫爬你网站的效能以及额度,因此在经营网站时一些最基础的事情你必须要尽量避免,像是:
- 网页尽量不要有无法访问的情况发生。
- 尽量避免不必要的重定向。
- 如果有产品/文章下架的话,记得把链接从网站上移除,避免消耗掉你的爬取额度;而且,如果不妥善移除已下架的商品或文章,对网站访问者来说体验也不太好。
今天的文章到这里就要结束了,希望能对你了解谷歌抓取的相关内容有所帮助。
来源公众号: 霆万科技(ID:TEAMONE_CE)专注品牌独立站数字营销
本文由 @Kenyth 原创发布于奇赞平台,未经许可,禁止转载、采集。
该文观点仅代表作者本人,奇赞平台仅提供信息存储空间服务。








