

Google Bot[1]的工作是在网络上发现网站、抓取和找到页面并将其添加到Google的索引中(出现在搜索页面)。但是网络空间非常大,Google Bot在抓取任何给定网站时只有有限的时间和资源,所以优化抓取速度很重要。
但从 Gary Illyes 近期的播客上说到,谷歌不会直接 follow 链接[2],而是先取链接,将它们收集到数据库中,然后再去逐个检查它们,如果有了解爬虫是什么的话,可以再去了解一下爬虫的工作机制,以及各种爬取比如深度、广度、权重爬取策略等。
为什么要关注抓取速率?抓取速率直接影响 Google 发现、索引和排名网站内容的速度。
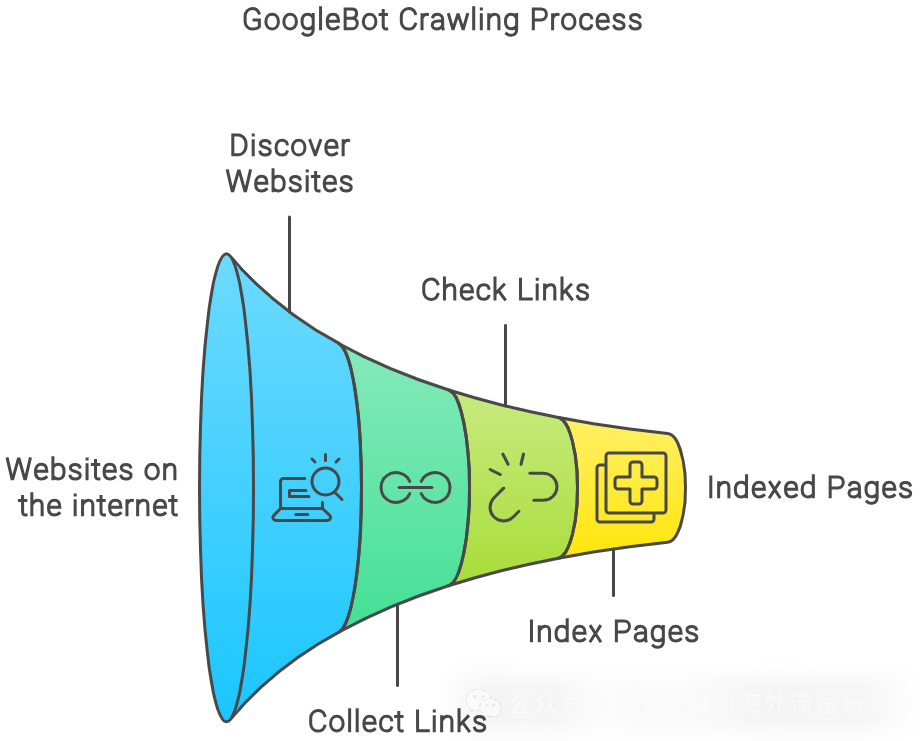
googlebot爬取页面的流程
怎么看爬取速率?
登录 Google Search Console[3] 即可:
- 1. 在左侧导航菜单中,找到并点击“设置”(Settings)。
- 2. 在“设置”页面上,找到“抓取统计信息”(Crawl Stats)[4]并点击进入。
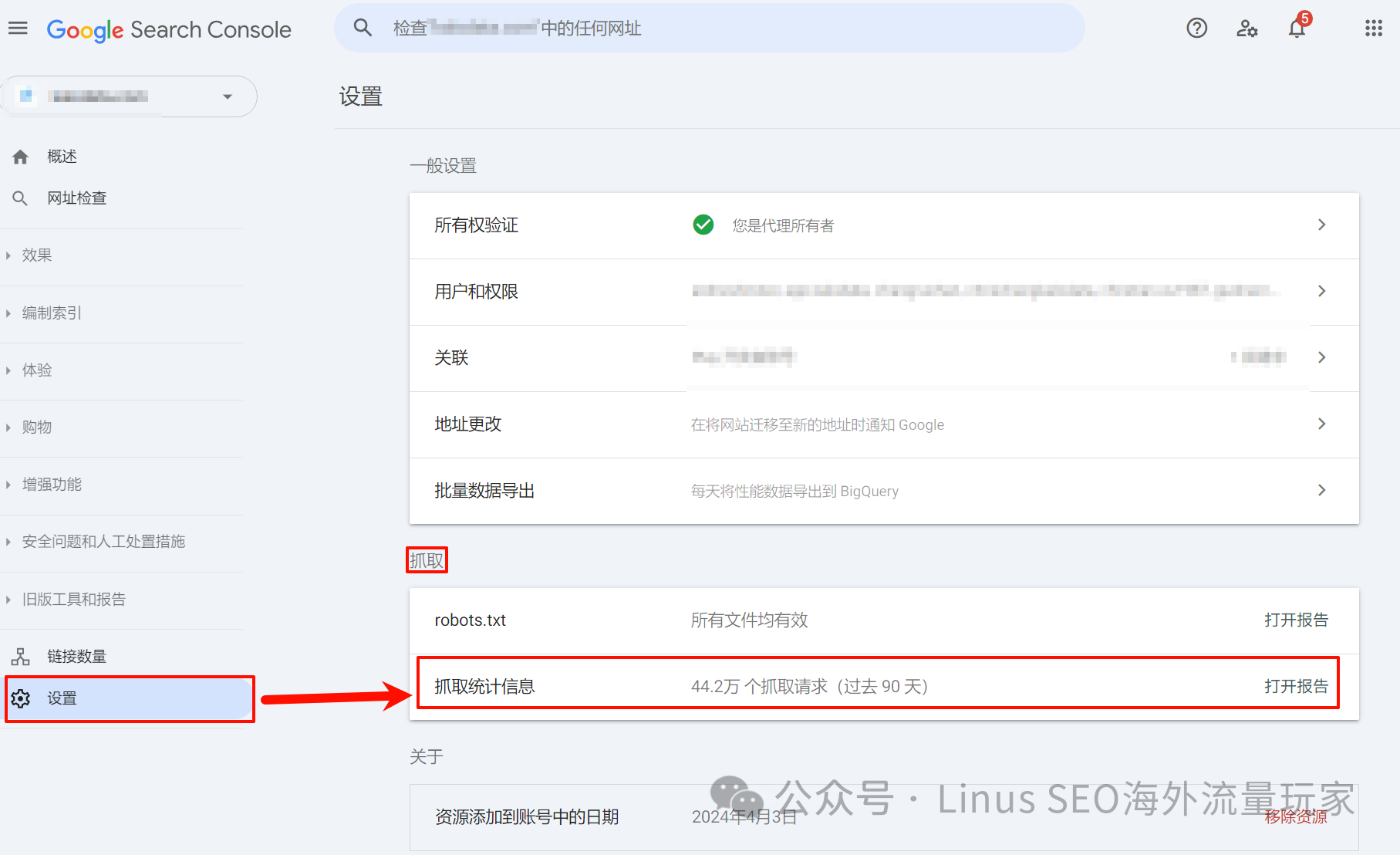
GSC打开抓取统计信息
怎么优化谷歌爬虫抓取?
• Robots.txt:这个看 robots 教程[5]就好,它具体会指明理应爬取什么。
• 利用 Sitemaps: 站点地图[6]可以帮助 Googlebot 了解站点的结构和重要页面的优先级,但一定要注意,站点地图不能有重复、异常的页面。除此之外,Priority 也是很重要的,例如,将畅销产品或新上架产品的优先级设置为高,将库存较少或即将下架的产品优先级设置为低。Shopify 对 sitemap 做了基础的分类,这也是一种方式:
• URL 参数:URL参数是附加在网页地址(URL)后面的查询字符串,用于传递信息或指令给服务器。通常,URL参数以问号 ? 开始,参数之间用 & 分隔,比如/page?category=shoes&color=red。如果你用了大量的查询参数,又没有指定规范化标签[7],就会让谷歌不断爬取不同参数的 URL,从而造成资源浪费。同样的,如果你有大量的重复内容,也需要使用 canonical URL。
• 避免无限爬取: 无限滚动的分页可能会导致Googlebot浪费资源在抓取不必要的页面上。这一点你可以看下谷歌的分页加载规范[8]。当然,以上 2 点有很多人也来用作有意或者无意的蜘蛛陷阱[9](Spider trap)——一种会在网站上陷入无限循环或重复抓取的情况。
• 监控抓取错误: 在抓取统计信息中,会显示当前的响应情况、信息,可以逐个点击进入查看。
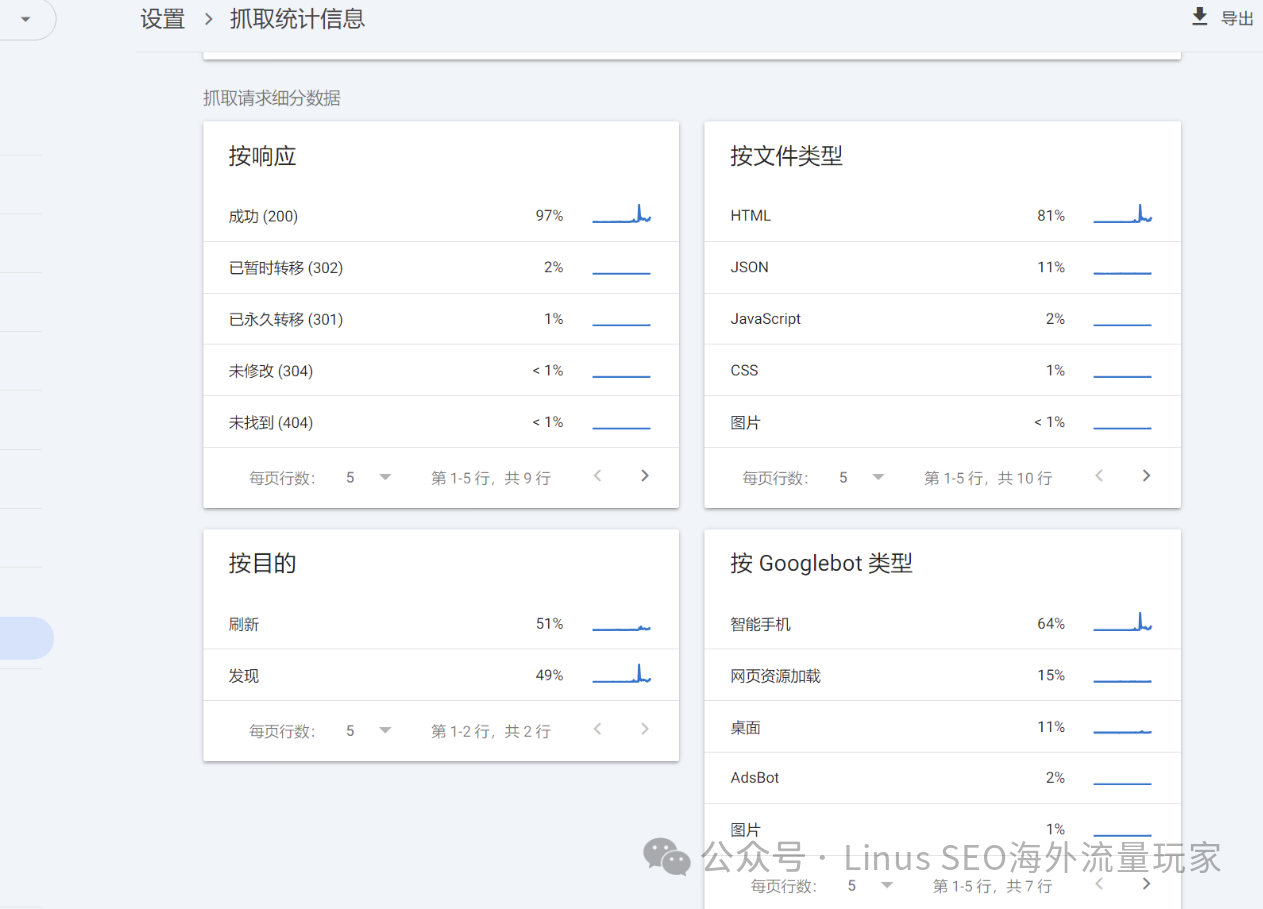
Googlebot爬取页面的状态
• 服务器端因素:如果遇到了 DNS问题或服务器阻塞等问题,也会可能产生抓取问题,这是一个坑点,有时会导致网站所有者误以为问题出在Googlebot上,所以可以先判断服务器有没有问题、分析日志的错误,是否因为抓取速率或者服务器返回了错误。
• If-Amendment-since 头: 这个 header 可以让 Googlebot 检查页面是否发生了更改,通过比较服务器返回的 Last-Modified 时间与 GoogleBot 本地缓存的页面时间,而无需再次下载整个内容,从而节省带宽和资源。
5 个谷歌爬虫抓取的认知误区
误区1. 网站越大,Googlebot 就会抓取越多的页面。
Googlebot 的抓取是基于算法和优先级的,它会优先抓取重要、高质量、更新频繁的页面,而不是简单地根据网站大小来决定抓取量。
误区2. 抓取越多,网站权重越高
普遍认为,谷歌机器人(Googlebot)越来越多的爬虫行为意味着网站质量越来越高。但这种假设具有误导性,仅仅因为 Googlebot 经常抓取网站并不一定意味着内容是好的。这也可能是由于其他因素,例如:
• 被入侵的网站: 如果一个网站被入侵,Googlebot 可能会抓取它更频繁索引新的网址创建的挂马中毒页面、外部恶意链接或者无效页面。
• 静态内容: 如果一个网站一段时间没有改变,Googlebot 可能会降低其爬行频率,但并不代表内容不行。
误区3. Googlebot 只抓取文本内容?
Googlebot 有不同等级的爬虫,谷歌爬虫还可以抓取和理解图片、视频、JavaScript 等多种类型的内容。但这不代表你就可以随心所欲用客户端渲染之类的“现代化”前端操作,必要的 SEO 页面规范还是要遵循的,静态化永远第一。
误区4. 增加网站内容就会自动提高 Googlebot 的抓取频率
虽然新内容可能会吸引 Googlebot 更频繁地访问网站,但抓取频率还受到其他因素的影响,如网站质量、更新频率、服务器性能等。另外,如果你的内容质量不佳(纯 AI、无个人见解),也会导致谷歌判定网站权重下降,从而导致抓取速率和频率下降。
误区5. 可以通过人工方式强制 Googlebot 更频繁地抓取网站
有这种方法,但比较灰黑帽 SEO[10],一般不会用,因为对于网站有伤害。实际上,Googlebot 的抓取频率由算法决定,人工干预通常无效,甚至可能适得其反。还有种说法是,降低抓取频率可以提高排名,这也是错误的,新内容无法被及时索引是非常大的 SEO 问题。
Google Bot谷歌爬虫的一些FAQs
• 要禁止 Googlebot 抓取一些网页? 使用 robots.txt 文件[11],指引各种搜索引擎的爬虫遵循规范(虽然不一定会遵循)。
• 不希望 Google 将某个或者某些网页编入索引?使用 noindex,禁止编入索引,并配合 GSC 的删除页面功能[12]。
• 需要完全阻止抓取工具或用户访问某个网页?请使用其他方法,例如密码保护[13],但从 SEO 角度,请不要使用地区保护方式(比如只限制某个国家地区访问或 IP 屏蔽),以防 Googlebot 混淆。
• 爬虫爬太快了,压力太大?Google 会自行确定最佳的网站抓取速度,如果你想要让抓取速度在短时间内减慢[14],则应向抓取请求返回 500、503 或 429[15] HTTP 响应状态代码(而非 200),如果实在不行,可以提交过度抓取报告[16]来降低爬取速率。
• Googlebot 会判断性能分数吗?不会,谷歌使用真实的 Chrome 使用数据来引入有关特定页面的核心网络生命周期的数据。其中包括 LCP、FID 和 CLS 分数[17]。Googlebot 抓取并不是 Google 获取此数据的来源,而是浏览器的实际访问行为。
谷歌爬虫算是非常基础且老生常谈的话题,Google 官方文档和各类资料都很齐全,遇到问题就具体情况具体分析。
参考链接
[1] Google Bot: https://developers.google.com/search/docs/crawling-indexing/googlebot?hl=zh-cn[2] 谷歌不会直接 follow 链接: https://www.seroundtable.com/google-follow-links-37892.html[3] Google Search Console: https://search.google.com/search-console[4] “抓取统计信息”(Crawl Stats): https://search.google.com/search-console/settings/crawl-stats[5] robots 教程: https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?hl=zh_cn[6] 站点地图: https://developers.google.com/search/docs/crawling-indexing/url-structure?hl=zh_cn[7] 规范化标签: https://www.semrush.com/blog/canonical-url-guide/[8] 分页加载规范: https://developers.google.com/search/docs/specialty/ecommerce/pagination-and-incremental-page-loading?hl=zh-cn[9] 蜘蛛陷阱: https://yoast.com/spider-trap/[10] 灰黑帽 SEO: https://seo.yiguotech.com/archives/what-is-white-hat-seo[11] robots.txt 文件: https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=zh-cn[12] GSC 的删除页面功能: https://search.google.com/search-console/removals[13] 其他方法,例如密码保护: https://developers.google.com/search/docs/crawling-indexing/control-what-you-share?hl=zh-cn[14] 让抓取速度在短时间内减慢: https://developers.google.com/search/docs/crawling-indexing/reduce-crawl-rate?hl=zh-cn[15] 429: https://www.webfx.com/web-development/glossary/http-status-codes/what-is-a-429-status-code/[16] 提交过度抓取报告: https://search.google.com/search-console/googlebot-report?hl=zh-cn[17] LCP、FID 和 CLS 分数: https://seo.yiguotech.com/archives/seo-web-core-vital-inp[18] 谷歌搜索中心近期的播客: Crawl smarter, not harder: https://youtu.be/UTAo-mfM75o[19] Gary Illyes在Linkedin上的关于GoogleBot的讨论: https://www.linkedin.com/posts/garyillyes_crawling-smarter-not-harder-activity-7228608152844337152-4H2b/
来源公众号: Linus SEO海外流量玩家(ID:neversec)跨境从业者,专长独立站SEO。
本文由 @Linus SEO海外流量玩家 原创发布于奇赞平台,未经许可,禁止转载、采集。
该文观点仅代表作者本人,奇赞平台仅提供信息存储空间服务。







