

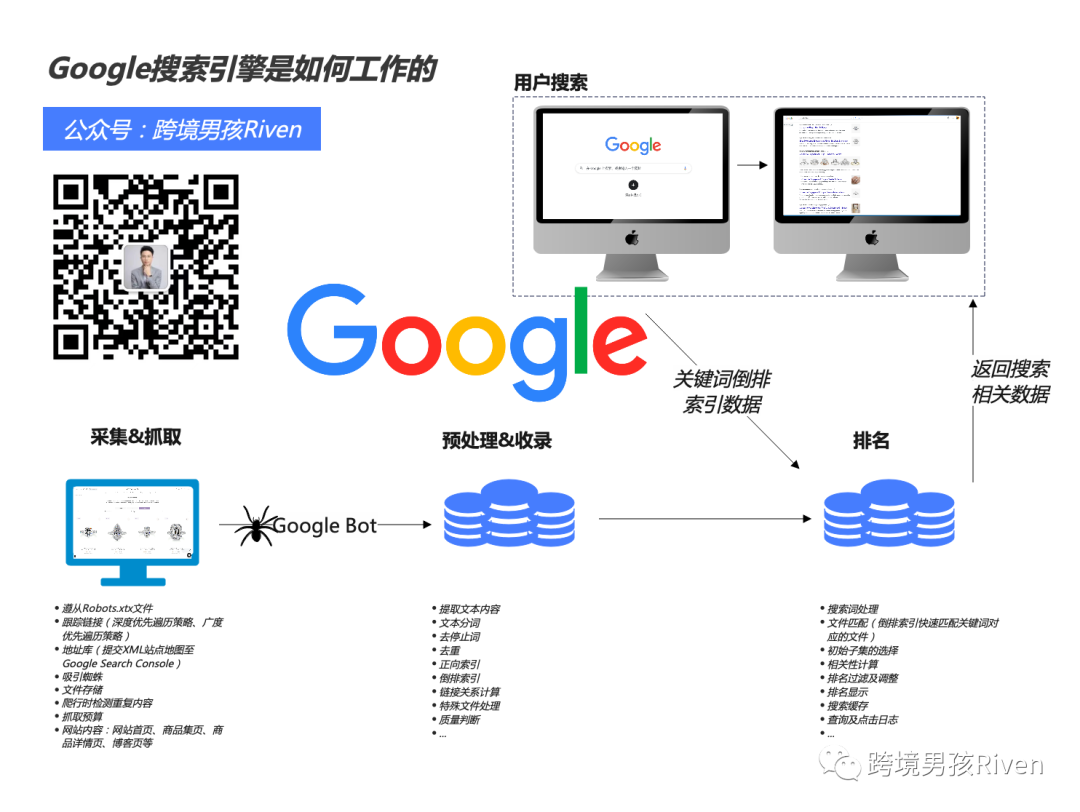
实际上Google搜索引擎技术的工作过程是非常复杂的,我在这里简单介绍下Google搜索引擎是怎样实现网页在SERP排名的,帮助做独立站SEO及从事互联网的朋友理解。
Google搜索引擎原理,最重要的三步:
- 蜘蛛爬行&抓取
- 预处理&收录(建立索引)
- 算法排序(提供搜索结果)
一:蜘蛛爬行&抓取
爬行和抓取是Google搜索引擎工作的第一步,完成对网络上存在的网站页面数据的采集任务。Google官方解释是 —— “抓取” 是指Google 使用称为抓取工具的自动化程序从其在互联网上找到的页面下载文本、图像和视频。
执行抓取的程序称为Googlebot (也称为机器人或蜘蛛)。Googlebot 使用算法过程来确定要抓取哪些网站、抓取频率以及从每个网站抓取多少页面。
Googlebot 会遵循Robots.txt文件中的协议,某些页面可能被网站所有者禁止抓取,蜘蛛就不会抓取。比如无法在不登录状访问的页面(如购物车页、结账页等)、重复页面等(如许多网站都可以通过域名的 www(www.domain.com)和非 www(domain.com) 版本访问)
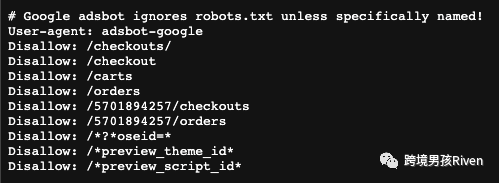
(某网站的Robots.txt文件)
Google可以通过对已知的页面实行深度和广度的遍历策略,去跟踪发现新页面和新内容,比如博客文章内发现产品链接(Inboud Links)等。
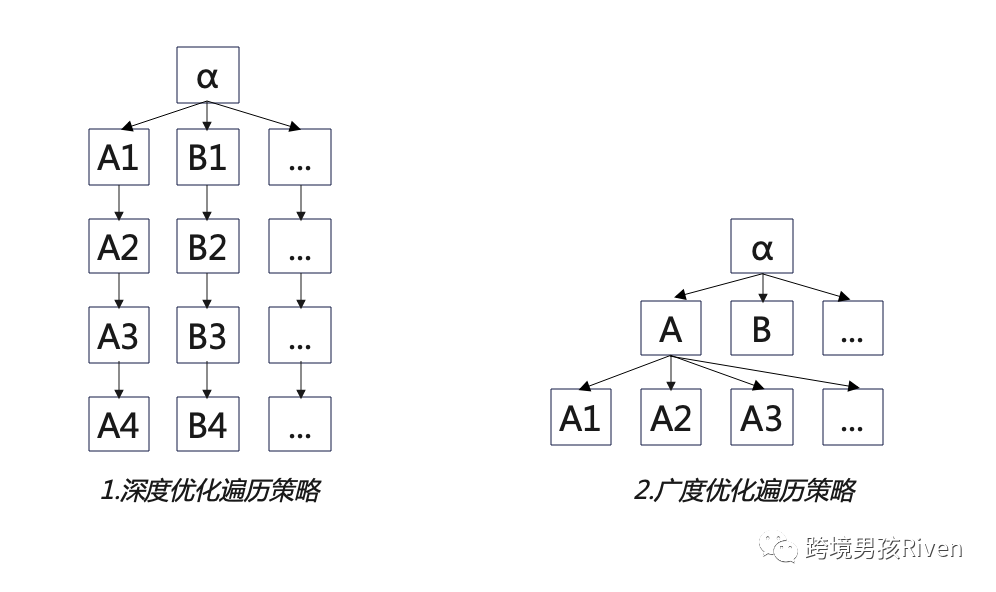
或者通过站长提交站点地图(Sitemap)到GSC(Google Search Console), Google 会参考Sitemap进行抓取,这也会发现到其他页面。
Googlebot抓取还会涉及其他知识方面:
- Robots.xtx文件
- 跟踪链接
- 地址库
- 吸引蜘蛛
- 文件存储
- 爬行时检测重复内容
- 抓取预算等
二:预处理&收录(建立索引)
预处理就是分析及处理抓取的网站数据内容;收录就是搜索引擎把页面存储到数据库的结果,也叫索引(Index)。
Google 的官方解释是—— “抓取页面后,Google 会尝试分析该页面的内容。这个阶段称为索引,它包括处理和分析文本内容和关键内容标签和属性,例如meta title、meta description、alt 属性、图像、视频等。”
Google会对抓取的原内容经过文字提取、分词、消噪、去重等后,得到独特、反映页面主要内容的、以词为单位的字符串。接下来就是搜索引擎索引程序就可以提取文件中的关键词,将URLs页面转换成一个关键词的集合。如下方所示:
| URLs | TDKU内容中的关键词 |
| URL-1 | 关键词1,关键词2,关键词8,关键词10,…,关键词A |
| URL-2 | 关键词2,关键词8,关键词20,关键词80,…,关键词B |
| URL-3 | 关键词2,关键词8,关键词20,关键词80,…,关键词M |
| ……. | |
| URL-N | 关键词3,关键词10,关键词71,关键词90,…,关键词N |
(正向索引示例)
接下来,搜索引擎会将正向索引数据库重新构造成为倒排索引,把URLs(或理解为URLs中内容文件)对应到关键词的映射关系转换为:关键词到URLs的映射。
在下面的倒排索引中,关键词是主键,每个关键词都对应着一些类文件或URLs,这些文件中都出现了这个关键词。这些数据会在下一阶段提供排名搜索结果中使用到。
| 关键词 | URLs |
| 关键词1 | URL-1,URL-2,URL-3,URL-9,…,URL-Q |
| 关键词2 | URL-9,URL-10,URL-11,URL-18,…,URL-W |
| 关键词3 | URL-8,URL-9,URL-10,URL-19,…,URL-E |
| ……. | ……. |
| 关键词N | URL-4,URL-5,URL-12,URL-21,…,URL-R |
(倒排索引示例)
Google收录还会涉及其他知识方面:
- 链接关系计算
- 特殊文件处理
- 质量判断等
三:排名(提供搜索结果)
在上一步GoogleBot收录了你的内容到Google 自己的搜索引擎数据库,收录了不代表立马有排名,Google对于新网站有个考察期,考察期内网站内容更新节奏比较稳定,没有恶意垃圾外链操作,Google开始慢慢放开给你排名。
当用户输入查询时,Google搜索引擎会在索引中搜索匹配页面,并返回Google认为质量最高且与用户最相关的结果。
这个过程就会用到第二点索引部分提到的倒排索引,使得文件匹配能够快速完成。
| 关键词 | URLs |
| 关键词1 | URL-1,URL-8,URL-3,URL-9,…,URL-Q |
| 关键词2 | URL-9,URL-10,URL-11,URL-18,…,URL-W |
| 关键词3 | URL-8,URL-9,URL-10,URL-19,…,URL-E |
| ……. | ……. |
| 关键词N | URL-4,URL-5,URL-12,URL-21,…,URL-R |
文件匹配(倒排索引快速匹配关键词对应的URL)
举个例子:若用户搜索”关键词3″,就会在SERP(搜索结果页面)展示URL-8,URL-9,URL-10,URL-19,…,URL-E。
若用户搜索”关键词1 and 关键词3″,排名程序只要在倒排索引中找到”关键词1 “和 “关键词3″这两个词,就能找到分别含有这两个关键词的所有页面,经过简单求页面交集即:URL-8和URL-9
但其实Google搜索引擎Rank的相关性由数百个因素决定,其中可能包括用户的位置、语言和设备(桌面或电话)、搜索意图等信息。
搜索引擎排名这块内容还涉及:
- 搜索词处理
- 初始子集的选择
- 相关性计算
- 排名过滤及调整
- 搜索缓存
- 查询及点击日志等
这里简单解释了Google搜索的工作原理,但Google一直在改进算法。建议可以关注Google Search Central 博客来了解Google更新内容 ,也感兴趣推荐阅读《SEO实战密码》、《SEO的艺术》、国外SEO博客站等。
来源公众号:跨境男孩Riven(ID:seoriven)从事多年跨境电商SaaS产研工作,深耕独立站、SEO领域。
本文 @奇赞 已获授权发布于奇赞平台,未经许可,禁止转载、采集。
已获授权发布于奇赞平台,未经许可,禁止转载、采集。
该文观点仅代表作者本人,奇赞平台仅提供信息存储空间服务。
如有侵权,请联系奇赞进行处理。







